
The rapid advancement of Large Language Models (LLMs) has significantly transformed the landscape of artificial intelligence, enabling machines to generate human-like text with unprecedented coherence and relevance. A pivotal development in this domain is Retrieval-Augmented Generation (RAG), a technique designed to enhance LLM outputs by integrating external information. However, the emergence of models like Meta’s Llama 4, boasting extensive context windows, has sparked discussions about the necessity and future of RAG. This article delves into the intricacies of RAG, the significance of context windows in LLMs, and evaluates whether advancements like Llama 4 render RAG obsolete.
Understanding Context Windows in LLMs
Context windows in LLMs refer to the amount of text the model can process in a single input. A larger context window allows the model to consider more information simultaneously, leading to more coherent and contextually relevant outputs. For prompt engineers and LLM users, understanding and effectively utilizing context windows is crucial for optimizing model performance. It enables the crafting of prompts that align with the model’s processing capabilities, ensuring that the generated responses are both accurate and contextually appropriate.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is a technique that enhances the capabilities of LLMs by incorporating external data sources into the generation process. Traditional LLMs rely solely on their training data to generate responses, which can lead to outdated or inaccurate information. RAG addresses this limitation by retrieving relevant information from external knowledge bases or documents and integrating it into the model’s input, thereby grounding the generated content in up-to-date and authoritative sources. This approach not only improves the accuracy of the responses but also allows the model to handle a broader range of topics without requiring extensive retraining.
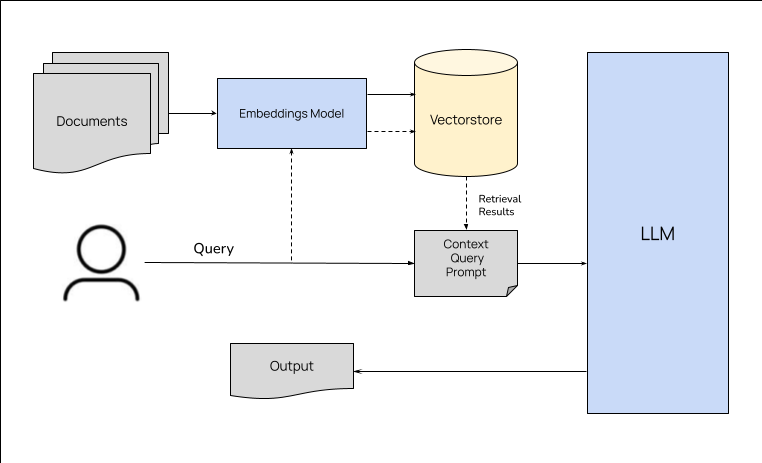
How RAG Works: A Technical Overview
The RAG process involves several key steps:
- Query Encoding: The user’s input query is encoded into a vector representation using an encoder model.
- Retrieval: This vector is used to search an external knowledge base, retrieving documents or passages that are semantically relevant to the query.
- Augmentation: The retrieved documents are combined with the original query to form an augmented input.
- Generation: This augmented input is fed into a decoder model, typically an LLM, which generates a response that incorporates information from both the original query and the retrieved documents.
This architecture allows the model to dynamically access and utilize external information, enhancing its ability to generate accurate and contextually rich responses.
Applications of RAG
RAG has been successfully applied across various domains:
- Customer Service: Enhancing chatbot responses by retrieving up-to-date product information and customer history, leading to more personalized and accurate interactions.
- Legal Research: Assisting in legal document drafting by retrieving relevant case laws and statutes, thereby improving the efficiency and accuracy of legal professionals.
- Healthcare: Providing clinicians with the latest medical research and patient data to support informed decision-making.
- E-commerce: Delivering personalized product recommendations by retrieving user preferences and browsing history.
These applications demonstrate RAG’s versatility in enhancing the functionality of AI systems by grounding them with external, authoritative information.
The Impact of Llama 4 on RAG
Meta’s Llama 4 introduces a substantial increase in context window size, capable of processing up to 10 million tokens in a single input. This advancement allows the model to handle extensive information internally, reducing the reliance on external retrieval mechanisms. However, this does not necessarily render RAG obsolete. While larger context windows enable the model to consider more information simultaneously, they do not address scenarios requiring real-time data or information beyond the model’s training cut-off. Moreover, processing such large inputs can be computationally expensive and may introduce latency, making RAG a more efficient solution in certain contexts.
Implications and Considerations
The expansion of context windows in models like Llama 4 presents both opportunities and challenges:
- Cost and Efficiency: Handling larger context windows requires significant computational resources, leading to increased operational costs. RAG offers a more cost-effective approach by retrieving only the necessary information, reducing the computational burden.
- Real-Time Information: LLMs with large context windows still rely on static training data. RAG enables models to access and incorporate real-time information, ensuring responses remain current and relevant.
- Domain-Specific Knowledge: For specialized fields, RAG allows models to retrieve and utilize domain-specific information without the need for extensive retraining, maintaining the model’s adaptability across various subjects.
These considerations highlight that while larger context windows enhance LLM capabilities, RAG remains a valuable technique for augmenting model performance, especially in scenarios requiring up-to-date or specialized information.
Conclusion: Is RAG Really Dead?
The advent of models with expansive context windows, such as Llama 4, has undoubtedly advanced the capabilities of LLMs. However, RAG continues to play a crucial role in scenarios where real-time data access, domain-specific knowledge, and computational efficiency are paramount.
References
https://en.wikipedia.org/wiki/Retrieval-augmented_generation?utm_source=chatgpt.com
https://www.databricks.com/glossary/retrieval-augmented-generation-rag?utm_source=chatgpt.com
https://ai.meta.com/blog/llama-4-multimodal-intelligence/

